Background
Suppose we want to create a service that allows authors to upload digital books to be stored in “the cloud.” Let’s also suppose that each book weighs in at 5 Mb, on average. We also want to compile some meta-data for each book so we can categorize an author’s library, select an excerpt from each book to serve as a good summary of its topic, and expose an author to others who write about similar subjects. Finally, let’s suppose that we have attracted the attention of scads of prolific authors, perhaps a million authors each having a hundred books to their name. Assuming no duplicates, we’re looking at about 475 Tb of data that need stored and processed.
Overview of a Solution
We begin with an overview of the components involved in receiving and processing all of these books. In the figure, concrete entities are represented by rounded rectangles while octagons are used to represent pools or clusters of entities. Solid lines are used to indicate the direction of communication between components. As a brief aside, when we refer to “authors”, we are really referring to authors and the software applications they are using to interact with our system.
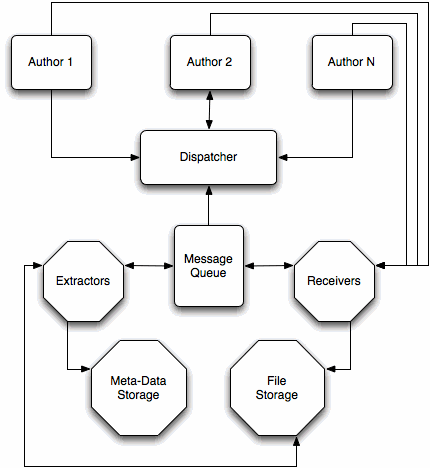
A summary of the steps involved in uploading a book to the system are:
- An
Authortells theDispatcherthat she has a book to upload. - The
Dispatcherreplies with the location of aReceiverthat is ready to handle the upload. - The
Authorconnects to the givenReceiverand begins transferring the book which theReceiverwrites toFile Storage. - When the upload completes, an available
Extractorgoes to work on the uploaded book, extracting the necessary meta-data. - The
Authortells theDispatcherthat she has another book to upload while theExtractoris culling information and storing it inMeta-Data Storage.
In the following sections, we will explore these interactions in greater detail and suggest some possible improvements to this system.
Transfer and Storage of the Books
The process begins when an author tells the central dispatcher that she has some books to upload. The dispatcher then makes an informed decision as to which receiver is available to handle the file transfer. The author connects to the receiver and sends her books which the receiver happily stores in “cloud” storage.
For simplicity, we’ll assume each receiver runs on its own server, virtual instance, etc. Receiving a single file across the Internet is typically not a CPU intensive operation because the CPU can process the data considerably faster than it can be transferred. This means a single receiver is capable of handling multiple uploads concurrently. The actual number of files a receiver can safely handle depends on the amount of bandwidth available to the server and the estimated transfer speed of an author.
When the dispatcher needs to find an available receiver to handle an upload, it broadcasts* its request through the message queue. If a receiver thinks it can handle the request it replies to the dispatcher, informing it of its current load and bandwidth availability. The dispatcher picks a sufficient receiver from these replies and routes the author’s request accordingly.
Once the upload has completed, the receiver passes a message to the extractors letting them know that a new book is ready to be processed and where that book resides within the file storage. The first available extractor consumes this message and quickly gets to work.
The use of a message queue to handle event dispatching incurs more overhead than if all of the components communicated directly; however there are some important advantages to this approach that will be covered in the section “The Value of a Message Queue”.
Extracting the Meta-data
Once a receiver has finished a transfer and written the book to the file storage, an available extractor begins harvesting the meta-data contained within the freshly uploaded book. The information it gathers is written to the meta-data storage (perhaps a RDBMS, or a NoSQL document store if we want more freedom in what constitutes meta-data.) When it finishes the extraction, the author now has a categorized and excerpted book in the system that connects them to other authors who have written something similar.
Again for simplicity, we’ll assume each extractor runs on its own server or VM instance. While the system’s file storage is likely network based, the transfer speeds will be considerably faster than the original transfer across the internet. Further, unlike copying a file, the meta-data extraction process is bound to require more computing power. As a result, a single extractor will not be able to handle as many books as a single receiver, but it may be able to handle several books concurrently, depending upon the resources available to it.
If the meta-data is successfully extracted, the extractor will notify the system of this event. This notification can be used to monitor overall system performance or to let a web application know that it should update the author’s profile. If the extractor fails to fully process the book, it could pass a message to the other extractors letting them know what data still needs extracted. If the book can’t be processed, for instance if it is in an unknown format, the extractor can pass along this information so that the author can be informed of the problem through an email, a web application or through the software they are using to upload their books.
The Value of a Message Queue
As mentioned earlier, using a message queue to handle all of the communication between components does incur some overhead. Each message has to be sent from one component to the broker where it is then dispatched to the other components that are listening for the message. The messages may be small, but there is still some non-zero propagation delay between one component sending the notification and another component receiving the message and responding to it. However, the additional flexibility a message queue offers will outweigh this overhead, especially when we need to quickly add or remove receivers and extractors.
If we take the intermediate broker out of our example, our dispatcher needs to be directly aware of all of the receivers. Further, the receivers need to be aware of all of the extractors. Typically this will require configuration files mapping out all of these relationships, and should you want to add more workers to the pool, you will need to update the config and deploy it to all existing workers so your new workers can start sharing in the load.
By having the message queue in place, any particular worker only needs to know where to find the message queue and the storage devices it needs to directly interact with. Receivers only need to know where the message queue is and where to store the books that they are receiving. Extractors need to know about the message queue, the meta-data storage and where to find books that have been uploaded. When a new worker comes online, it tells the message queue what notifications it cares about through subscriptions.
In our hypothetical book storage system, the dispatcher will subscribe to an “available receivers” topic, and broadcast messages to a “request for receiver” topic when it needs to connect an author with a receiver. Each receiver will subscribe to the “request for receiver” topic, waiting for the dispatcher to ask it for help, and will pass a message to a “book uploaded” queue every time a new book is uploaded. Finally, our extractors subscribe to the “book uploaded” queue and a “retry extraction” queue. As these are queues instead of topics, the messages passed here will be consumed by one and only one extractor. If the extraction completes successfully, the extractor can pass a message to “book completed” topic. If the extraction could not be finished it can signal this through the “retry extraction” queue, allowing another extractor to consume the message and continue the work.
A big advantage here is that if a surge of new authors discover our service and start uploading their works, we can spin up new workers to handle the increase in demand without doing much work. The message queue maintains an internal list of active sessions and their corresponding subscriptions so the workers just need to know where to find the broker.
Another advantage to having this infrastructure in place is that it makes introducing and responding to new events fairly trivial. Let’s say we want our system to automatically grow and shrink in response to demand so if a flood of new authors show up at 4 AM on a Saturday, no one’s trying to spin up new virtual instances with a hangover. One way to accommodate this feature would be to introduce a few system monitors, we’d want more than one for redundancy’s sake. These monitors subscribe to the “request for receiver,” “available receivers,” and “book completed” topics. From here, they can measure how often the dispatcher is making requests for receivers, what kind of load each available receiver is under and how long it is taking the extractors to do their magic, and that’s enough information to anticipate the need for more (or fewer, if demand drops) receivers and extractors. The monitors can now spin up and spin down other instances without changing* how the other components in the system operate.
Glossed Over Details and Suggested Improvements
Tracking the Overall Job
The system outlined here performs its work based upon the production and consumption of simple event messages passed through the message queue. When the receiver finishes storing a new book, it only tells an extractor where to find the file. We have not given the system a way to determine the overall process of a particular “job.” Fortunately, most message queues allow for headers to be attached to any message, and this will allow us to better track where a book is in the processing pipeline. If the dispatcher gives an author the address of a receiver and a session key when she starts the uploading process, she can in turn provide the receiver with this key. Now, every message the receiver passes to the queue will contain this session key as a message header and all consumers (namely the extractors) of these messages will copy that header to the messages they produce. From there, we can either passively monitor the progress of a book by tracking the session key header, or we can actively poll workers for status updates for a given session key. The latter will require some additional logic to be built in to our workers.
Working in Bulk
One way to reduce the relative chatter between components and the message queue is for the system to prefer to work on batches of books whenever possible instead of processing one book at a time. This doesn’t reduce the number of messages being passed, but it does mean that fewer messages are being passed per book.
Fault Tolerant Dispatching
As outlined here, the dispatcher is a single point of failure. We can improve upon this design by creating a dispatcher pool and using DNS load balancing to distribute the requests. Alternatively, it may be possible to remove the need for dispatchers all together by having authors connect directly to receivers by way of some content delivery network, though this option will depend upon the particular “cloud service provider” being used.
Letting Authors Pull Their Weight
Generating a social graph for an author based upon the subjects of her works requires information that is available only within our service. However, personal categorization of her library and extracting excerpts from her books can be done using only the information available on the author’s computer. Why not let her computer share in the work? After her library has been analyzed, she’ll transfer the book along with the meta-data produced locally, giving our extractors more free time to spend with their families! Our simplified message passing would need to be adjusted to accommodate this scenario, of course, but being able to reduce the number of VM instances probably warrants the adjustment.
Maybe we can go further. Authors probably like to keep their books organized, maybe the software they use to write books allows them to add meta-data elements like keywords, an abstract, and so forth. Wouldn’t it be nice if the software they use to interact with our service could talk to the software they already use to keep tabs on their books? Maybe their software doesn’t have all of the meta-data we’re after, maybe its ability to organize books is pretty limited (Kindle…) Our extractors may have to do some work, but any meta-data we can provide before our system starts processing will certainly reduce the time it takes an author to have their full library available in the cloud.
Footnotes
Note: Topics and Queues
The particulars will vary between message queue services,
but it is common for message queues to support two types of destinations:
queues and topics. Messages passed to a queue are delivered to a
single subscriber (a receiver in our example) while those passed to a
topic are delivered to all subscribers.
[ jump back ]
Note: Monitors
I lied a little bit, though I’m choosing to call it a simplification. In reality, if a monitor were to spin down a receiver while it was handling an upload, the system we’ve been discussing would break. The monitor should, instead, politely ask that a receiver stop taking new requests and when said receiver has completed its current requests, it would gracefully shut itself down. While we’re on the subject of omissions through simplification, if a receiver were to fail to receive a book, we could have it send an “upload failed” notification, providing the dispatcher with the opportunity to notify the author that she needs to re-send the book to a newly determined available receiver. [ jump back ]